
Node.js에서 Batch Performance 향상과 많은 데이터를 청크 처리하기
NestJS Batch Job
현재 다니고 있는 미국 회사에서 한국 비즈니스 환경에 맞게 개발된 Github Template 기반으로 Job 프로젝트를 생성하여 배치를 개발하고 있다.
아직은 NestJS는 Spring Batch와 같은 프레임워크와 비교했을 때, 자체적으로 지원하는 배치 기능을 제공하지 않아 이런 한계를 극복하기위해 사내 프레임워크로 커스터마이징하여 NestJS 모듈화 및 사내 라이브러리로써 필요한 기능을 구현하고 있다.
Job template simple code
start(jobExecutionId: number) {
return this.jobExecutionManager.run(() => {
return new JobBuilder()
.start(...)
.createLog(...)
.concurrency(number) // 동시성 모드 실행 ON
.task(...)
.task(...)
.afterTask(...)
.build();
}, jobExecutionId);
}
위 코드에서 start 를 하면 Job 실행을 위한 리소스들을 가져온다.
createLog 에서는 이 Job을 실행 하겠다는 알림 및 로그를 생성한다.
task 는 Job 실행의 서비스 단위이다(이것을 여러개 선언하면 task들이 step별로 실행된다.)
첫 번째 task는 4초가 소요, 두번째 task는 2초가 소요된다고 가정한다.
concurrency 옵션을 사용 시, 적절한 값의 동시성 수를 설정하여 실행을 최적화 해야한다.
.task(() => delayFourSeconds())→ 4초 소요.task(() => delayTwoSeconds())→ 2초 소요
concurrency(number)가 활성화 돼 있을 경우, 두번째 task가 첫번째 task가 끝날 때 까지 기다리지 않고 실행 되기 때문에 성능의 이점을 누릴 수 있다.
afterTask 실행이 완료되면 최종적으로 실행 종료 로그 생성과 Job 실행을 종료한다.
Chunk processing
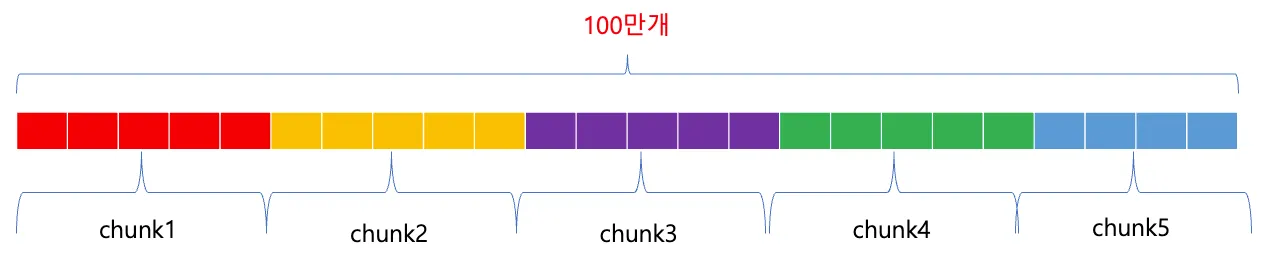
Chunk processing은 데이터를 작은 덩어리로 나누어 처리하는 방법을 가리킨다. 이는 대규모 데이터를 작은 단위로 분할하여 병렬적으로 처리함으로써 성능을 향상시키는 것을 의미한다.
백엔드에서는 주로 네트워크 트래픽, 데이터베이스 쿼리, 파일 처리 등의 작업을 효율적으로 처리하기 위해 Chunk processing을 활용할 수 있다.
이러한 방식은 대규모 시스템에서 확장성과 성능을 개선하는 데 도움이 될 수 있다.
아래의 예시를 살펴보자.

일반적으로 100개의 데이터를 한번에 처리하는 것은 가능하다.

그러나, 100만개의 row를 가진 DB의 결과 값을 처리한다고 하면, 100만개의 데이터를 조회하는 서버에서 메모리에 올려야 하는 문제와 이것을 처리하는 과정에서 커넥션 타임아웃의 문제 등 여러가지 이슈들이 발생될 수 있으므로 이것을 효율적으로 해결하기 위해서는 Chunk processing 이라는 방법을 사용하여 해결 할 수 있다.
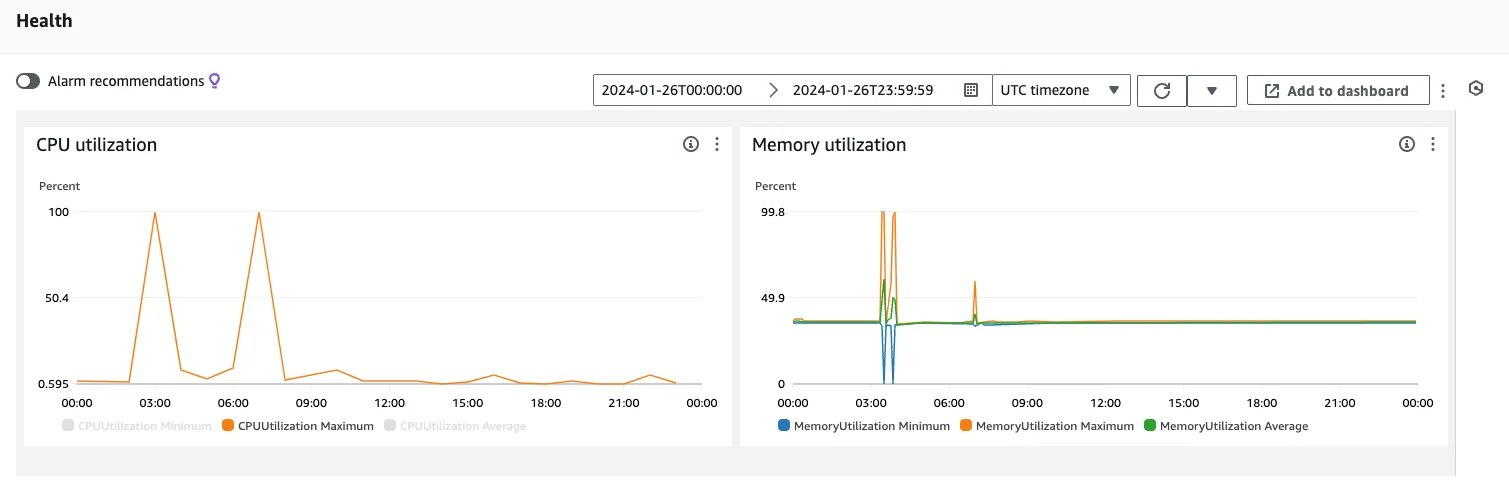
2024년 1월 26일 서비스 장애
- 아래의 그래프를 보면 1월 26일 특정 시간에 Batch Job 서비스에서 많은 데이터를 조회하여 메시지 서비스로 많은 요청했다.
- 2024년 1월 26일 - 메시지 서비스가 특정 시간에 CPU와 Memory 사용량이 100%를 찍었고 메시지 서비스가 죽어버렸다.
많은 데이터를 chunk 단위로 분할 처리
Chunk processing sample Code
위 문제를 해결 하기 위해 내가 만든 라이브러리를 사용했다. (이 라이브러리는 public이지만, 사내용으로 만들어진 private Arehs는 사내 환경에 맞게 커스텀 되었음)
import { Arehs } from "arehs";
const users = [
{ id: 1, name: "John" },
{ id: 2, name: "Alice" },
{ id: 3, name: "Bob" },
...
];
const result = await Arehs.create(users)
.withConcurrency(1000)
.mapAsync(async user => {
return await someAsyncFunction(user);
});
위 코드를 실행하면 100만명의 User를 대상으로 한번에 많은 자원을 요구하여 복잡적인 문제가 발생하여 시스템에 장애를 일으킬 수 있으므로 withConcurrency 를 1000개로 설정하고 실행한다.(많은 테스트를 통해 최적의 Chunk 수를 구해야함)
Chunk size 만큼 비례한 I/O가 발생하는 쿼리 함께 개선하기(Bulk Insert)
문제의 Sample Code
Chunk 단위로 프로세싱을 하지 않는 코드에서는 아래와 같이 N개의 Insert를 수행하게된다.
await Promise.all(
users.map((user) =>
this.repository.createBatchQueue({
batchQueueId: uuid(),
targetId: user.targetId,
dateGroup: today.date,
weekDay: today.weekdayEn,
batchQueueCreatedDate: batchQueueCreatedDate
})
)
)
위 코드를 실행하면 N개의 Insert를 수행한다.
실행된 쿼리
INSERT INTO CUSTOMER.ADDITIONAL_COMPENSATION_BATCH_QUEUE
(BATCH_QUEUE_ID, TARGET_ID, DATE_GROUP, WEEKDAY, CREATED_DATE, CREATED_BY)
VALUES(...);
INSERT INTO CUSTOMER.ADDITIONAL_COMPENSATION_BATCH_QUEUE
(BATCH_QUEUE_ID, TARGET_ID, DATE_GROUP, WEEKDAY, CREATED_DATE, CREATED_BY)
VALUES(...);
INSERT INTO CUSTOMER.ADDITIONAL_COMPENSATION_BATCH_QUEUE
(BATCH_QUEUE_ID, TARGET_ID, DATE_GROUP, WEEKDAY, CREATED_DATE, CREATED_BY)
VALUES(...);
-- ... N개
문제 해결을 위한 I/O 최소화 및 Bulk Insert로 전환
위 코드에서는 loop를 돌 때 마다 createBatchQueue 함수를 실행하여 많은 insert가 N개 만큼 발생했지만,
아래의 코드에서는 Bulk Insert를 위한 유저들을 미리 구하고 한번만 실행한다.
const pendingUsersCreationQueue = users.map((user) => {
const batchQueue: BatchQueue = {
batchQueueId: uuid(),
targetId: user.targetId,
dateGroup: today.date,
weekDay: today.weekdayEn,
batchQueueCreatedDate: batchQueueCreatedDate
};
return batchQueue;
});
await this.repository.createBatchQueue(pendingUsersCreationQueue);
개선된 쿼리
createBatchQueue() 쿼리 실행 함수에 pendingUsersCreationQueue 파라미터를 넘기고, static 함수인 CollectionUtils.toBulkInsertMultiValueString()에서 bulk를 위한 파싱된 결과를 리턴함.
const createBatchQueue = (pendingUsersCreationQueue: BatchQueue[]) => {
const values = CollectionUtils.toBulkInsertMultiValueString(
pendingUsersCreationQueue,
);
return `
INSERT INTO CUSTOMER.ADDITIONAL_COMPENSATION_BATCH_QUEUE
(BATCH_QUEUE_ID, TARGET_ID, DATE_GROUP, WEEKDAY, CREATED_DATE, CREATED_BY)
VALUES ${values};
`;
};
😣 개선전 실행 쿼리 (N개의 INSERT)
INSERT INTO CUSTOMER.ADDITIONAL_COMPENSATION_BATCH_QUEUE
(BATCH_QUEUE_ID, TARGET_ID, DATE_GROUP, WEEKDAY, CREATED_DATE, CREATED_BY)
VALUES(...);
INSERT INTO CUSTOMER.ADDITIONAL_COMPENSATION_BATCH_QUEUE
(BATCH_QUEUE_ID, TARGET_ID, DATE_GROUP, WEEKDAY, CREATED_DATE, CREATED_BY)
VALUES(...);
INSERT INTO CUSTOMER.ADDITIONAL_COMPENSATION_BATCH_QUEUE
(BATCH_QUEUE_ID, TARGET_ID, DATE_GROUP, WEEKDAY, CREATED_DATE, CREATED_BY)
VALUES(...);
-- ... N개의 INSERT가 생성됨.
😀 개선된 실행 쿼리 (Bulk Insert로 1회만 수행)
Bulk Insert에 대한 기준은 데이터베이스 시스템, 하드웨어 자원, 애플리케이션의 요구 사항에 따라 다를 수 있다.
그래서 Bulk Insert를 꼭 1회 실행한다는 의미가 아니라 트랜잭션 문제(롤백 시 성능 이슈), 메모리 이슈, Lock 이슈 등을 고려해야한다.
만약 1억 건의 데이터를 처리하기 위해서 백만 건이상 씩 분할하여 처리하는 기준을 세우는 등의 성능 테스트를 하는 것이 중요하다.
INSERT INTO CUSTOMER.ADDITIONAL_COMPENSATION_BATCH_QUEUE
(BATCH_QUEUE_ID, TARGET_ID, DATE_GROUP, WEEKDAY, CREATED_DATE, CREATED_BY)
VALUES
("1EEBDD91DDBC08C0AFA22F0A838D7965", ...),
("1EEBDD91DDBE0FD0AFA22F0A838D7965", ...),
-- (...),
-- (...),
-- (...),
-- (...),
-- .......
("1EEBDD91DDBE0FD0AFA22F0A838D7965", ...);
결과
메시지 서비스가 2024년 1월 26일 장애 이후, 1월 29일부터 CPU와 Memory 사용량이 눈에 띄게 감소하였다.
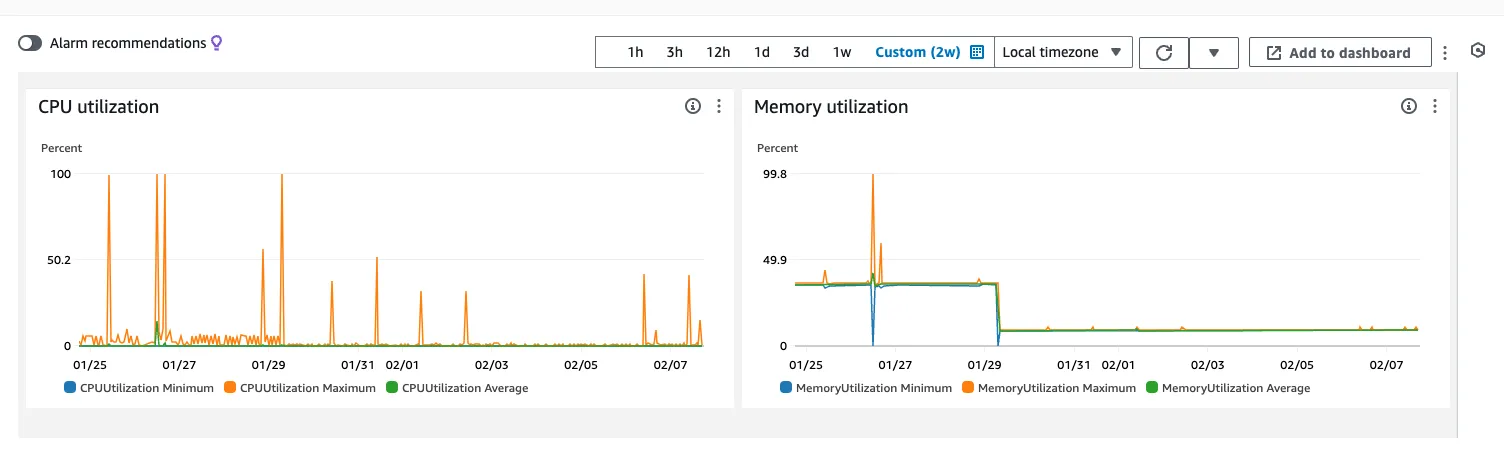
메시지 서비스가 2024년 1월 26일 장애 이후, 1월 29일부터 CPU와 Memory 사용량이 눈에 띄게 감소
- 기존에는 N개의 데이터를 N개 만큼 처리를 하였다. (장애 발생)
- N개의 데이터를 Chunk Size만큼 처리함.
- Chunk Size 만큼의 I/O가 발생할 수 있기 때문에 Bulk Insert 전환으로 일부 쿼리 I/O를 최대 1회만 수행할 수 있게 개선
위 처럼 1월 26일부터 많은 데이터를 처리하는 과정에서 장애가 발생하였고, 1월 29일부터 CPU와 메모리 사용량이 많이 줄어들어 안정적인 서비스를 운영할 수 있게 되었다.